Article de l'axe stratégique de la MOM "Les données de la recherche, de l'acquisition à l'archivage"
Du 14 au 18 octobre 2019 à Aussois s’est déroulée l’école thématique DONIPAT (DONnées Interopérables pour le PATrimoine) organisée par le consortium MASA (Mémoire des Archéologues et des Sites Archéologiques) de la TGIR Huma-Num. Elle avait pour ambition de présenter les avancées du consortium en matière d’interopérabilité des données et de témoigner de son intérêt auprès de la communauté des SHS. Au sein du service informatique (PSIR) de la MOM, nous sommes en cours de modélisation du jeu de données de la fouille de Kition-Pervolia (Chypre) avec l’ontologie du CIDOC-CRM. Nous intégrons cette démarche au sein de nos activités MASA en utilisant le modèle OpenArchaeo développé par Olivier Marlet au CITERES de la MSH Val de Loire.
Ce modèle générique, dédié à l’archéologie, permet d’optimiser l’appariement des concepts partagés par la plupart des jeux de données archéologiques pour qu’ils soient accessibles et interrogeables. Une plateforme, du même nom, repose sur ce modèle et permet la mise à disposition et l’interrogation sur le web sémantique des jeux de données. Lorsque la modélisation de Kition-Pervolia sera terminée, des requêtes seront testées sur le jeu de données de la MOM et sur ceux de MASA pour éprouver la solidité et la compatibilité du modèle OpenArchaeo avec des données hétérogènes.
La semaine s’est décomposée en deux grands ensembles, la première partie de la semaine était consacrée à la conceptualisation, à la définition d’une ontologie et à différentes présentations de cas exemples illustrant leurs usages.
La seconde partie de la semaine était centrée autour du CIDOC-CRM et revêtait un aspect plus pratique avec la démonstration de différents outils pour la modélisation, l’appariement et la manipulation de données interopérables.
3M (Mapping Memory Manager) : comment apparier un fichier XML avec le CIDOC-CRM
Nous allons aborder la partie technique de prise en main d’un outil pour la manipulation et l’appariement des données. Le fichier XML d’un jeu de données, aboutit à des triplets RDF (Ressource Description Framework, qui décrivent formellement une ressource et ses métadonnées), modélisés avec l’ontologie du CIDOC-CRM, aptes à être déposés dans un Triple Store (une base de données dédiée aux triplets RDF) et que l’on peut interroger par des requêtes. Ce billet est volontairement technique et démonstratif, mais il permet d’introduire les bases de la manipulation de cet outil qui peut rebuter lorsque l’on débute.
Un prérequis essentiel à l’utilisation de 3M est un fichier XML correctement formé. L’appariement n’est pas un processus aisé et si le fichier source est mal formé ce sont des obstacles supplémentaires qui rendent le travail fastidieux.
● Qu’est-ce que le CIDOC-CRM ?
Avant de débuter le détail de la manipulation technique, il convient de faire un court rappel de ce qu’est une ontologie et surtout le CIDOC-CRM. Une ontologie est une taxonomie de haut niveau d’un domaine de connaissances. Autrement dit, c’est un ensemble structuré de descriptions unies entre elles par une série de relations. Les "classes" sont pour les concepts décrits et les "propriétés" pour les liens qui unissent les classes. Une ontologie doit rendre explicite tout l’implicite. On part du principe que tout ce qui n’est pas explicite n’existe pas car cela bloque la compréhension de l’objet que l’on modélise. C’est une représentation de la sémantique sous-jacente des structures de la documentation. Une ontologie prend également en compte la notion d’héritage. Une taxonomie implique une hiérarchie "parent" vers "enfant". L’enfant héritant de l’ensemble des caractéristiques de son parent, sinon le raisonnement ne fonctionne pas.
Le CIDOC-CRM est une ontologie évènementielle à fort niveau d’abstraction développée par le Comité International pour la DOCumentation (CIDOC) de l’International Council Of Museum (ICOM). Le CIDOC est un modèle conceptuel de référence (Conceptual Reference Model : CRM). Les premiers travaux débutent en 1996 et se poursuivent depuis. Ils cherchent à atteindre le monde des bibliothèques, des archives, de l’archéologie, etc. Depuis 2006 le CIDOC-CRM est devenu une norme ISO (ISO 21127:2006), mise à jour en 2014 (ISO 21127:2014). Il a pour objet le patrimoine culturel. Il est un standard qui permet d’intégrer l’information culturelle. L’objectif est de pouvoir interroger différentes sources en simultané, modélisées selon un schéma identique. L’interrogation est donc plus poussée que si l’on traite toutes les sources les unes après les autres et que l’on croise les résultats à postériori. L’ontologie est composée de classes reliées entre elles par des propriétés, réversibles ou non, qui définissent un enchainement logique pour caractériser des informations. Plusieurs extensions existent dans le but de spécifier finement certains domaines (FRBRoo : bibliographique (monographie), PRESSoo : bibliographique (série, revue), CRMinf : argumentaire, CRMarcheo : archéologie, CRMsci : observation scientifique, CRMgeo : spatiotemporel, CRMdig : métadonnée, CRMba : archéologie du bâti, CRMtex : texte ancien, CRMsoc : social).
● Qu’est-ce que le modèle OpenArchaeo ?
Le modèle OpenArchaeo est la concrétisation de tout le travail sur l’interopérabilité du consortium MASA sous la forme d’une plateforme développée en partenariat avec la société SPARNA (développeur du service Nakala d’Huma-Num). Sa finalité est de proposer une mise à disposition sur le web sémantique de jeux de données archéologiques produits au sein du consortium MASA et modélisés à l’aide de l’ontologie du CIDOC-CRM. Cette plateforme est aussi un moyen d’interroger les données avec une interface graphique accessible à tous. OpenArchaeo est aussi un modèle générique permettant de relier les concepts ontologiques partagés par la plupart des jeux de données en archéologie, rendant par ce principe les données interopérables entre elles. L’interopérabilité permet des interrogations groupées comme un seul et même ensemble. Le langage utilisé pour les requêtes est le SPARQL (un langage permettant la manipulation des données RDF disponibles sur le web).
● Mais à quoi cela sert-il ?
3M est un outil intermédiaire dans le processus de traitement d’un jeu de données. Il intervient juste après la modélisation. Elle doit être, dans un premier temps, conceptuelle avant de s’appliquer aux données. La modélisation des données nécessite de sélectionner le niveau hiérarchique correspondant à l’information que l’on décrit au sein de l’ontologie. Plus la classe est élevée dans la hiérarchie, plus elle est générale. A l’inverse, une classe très spécifique se trouvera très bas dans la hiérarchie. Des outils tels que Protégé, DIA ou YED aident aux ajustements de cette étape. 3M sert à faire correspondre une ressource avec une des classes du CIDOC-CRM en respectant ses règles hiérarchiques d’héritage. La finalité est d’obtenir une série de triplets RDF qui sont les plus petites unités de description d’une ressource. On peut les déposer alors dans un triple store au sein duquel les données sont toutes reliées entre elles. Pour qu’il soit intelligible, le triplet doit contenir un sujet (la ressource à décrire), un prédicat (la relation applicable à cette ressource) et un objet (la ressource en elle-même). La synthèse de ces trois éléments permet de décrire de manière formelle les ressources web et leurs métadonnées en permettant un traitement automatisé de celles-ci. Il faut bien distinguer un triple store d’une base de données classique, la finalité de l’interrogation n’est pas la même. Avec des requêtes sur un triple store, on cherche à interroger ce qui décrit les ressources et non pas les ressources en elles-mêmes comme dans une base de données classique.
● Mapping Memory Manager (3M) et Ontop
Il existe principalement deux outils pour réaliser l’appariement des données, 3M et Ontop. Les deux outils répondent à des besoins spécifiques en matière de type de données. Pour 3M, l’idée est d’avoir un fichier de données dites plates issues par exemple d’un tableur, alors qu’Ontop récupère les données depuis une base de données relationnelle. L’utilisation de 3M nous parait moins abrupte pour un débutant que celle d’Ontop puisque l’on peut utiliser un navigateur web avec une interface graphique. Pour ce dernier il faut installer le logiciel et avoir un petit outil de base de données PHP. C’est pour cela que nous allons utiliser 3M comme exemple dans la suite de ce billet. Il existe bien entendu d’autres outils pour faire les appariements tel que Karma ou bien OntoMe, mais nous ne les aborderons pas ici car nous ne les avons pas manipulés lors de la semaine DONIPAT.
● Comment faire un appariement avec 3M ?
Pour pousser un peu plus la démonstration, nous allons présenter le cheminement d’un appariement en utilisant 3M avec lequel nous avons l’habitude de travailler au PSIR. 3M est un outil développé par l’ICS-Forth à Héraklion en Crête. Pour cet exemple nous utiliserons le jeu de données de Kition-Pervolia issu de la fouille d’une nécropole du chypriote moyen (IIe millénaire av. J.-C.) au chypriote récent (XIIe siècle av. J.-C.) qui s’est déroulée entre 2008 et 2012, à Chypre, sous la direction de Sabine Fourrier (HISOMA). 3M existe en deux versions, une première avec une interface graphique utilisable depuis un navigateur. Elle est, de prime abord, plus conviviale pour un débutant. La seconde interface est un moteur X3ML en ligne de commande que l’on peut télécharger sur le GitHub du projet. Il faut toutefois noter une petite limitation de l’interface graphique. Elle ne peut traiter un trop grand volume de données. C’est pour cela que nous n’utiliserons l’interface graphique que dans le cadre d’une première étape d’ajustement de l’appariement avec un échantillon de nos données. Puis nous transformerons l’ensemble à l’aide de la version en ligne de commande. L’intérêt de cette interface graphique est de pouvoir tester son appariement sur un échantillon sans devoir manipuler un fichier XML de plusieurs dizaines de milliers de lignes et ainsi allonger le traitement.
La première étape de l’appariement dans 3M est l’import du fichier au format XML. Comme étape préalable il sera donc peut-être nécessaire, d’exporter un tableur en un fichier XML, ce qui peut nécessiter un petit travail de mise en forme des données pour préparer le balisage du fichier.
1 : Fichier XML échantillon (cliquer pour agrandir l'image)

On peut donc débuter par l’importation dans l’interface graphique d’un échantillon de son jeu de données qui soit représentatif de l’ensemble. Il faut ensuite ajouter les différents modèles avec lesquels on souhaite réaliser l’appariement, à minima le schéma du CIDOC-CRM et si nécessaire les extensions plus spécifiques comme le CRMArcheo, CRMSci, SKOS Label… L’ajout des extensions permet d’utiliser des classes et propriétés dédiées pour les données spécifiques. On peut alors utiliser des niveaux hiérarchiques de très bas niveau et donc très spécialisés. Le CIDOC-CRM étant un modèle pour les données du patrimoine culturel dans toutes leur diversité, les extensions « métier » permettent un niveau de spécification plus important. Le but de cette pré-sélection est d’éviter de véhiculer l’intégralité des choix d’appariement et de se restreindre uniquement aux ensembles de classes qui seront utiles à notre jeu de données. Par exemple pour la modélisation d’une collection d’objets archéologiques il peut ne pas être nécessaire d’ajouter l’extension du CRMsoc qui concerne la modélisation de la documentation sociale.
2 : Page d’accueil de 3M avec interface graphique (cliquer pour agrandir l'image)
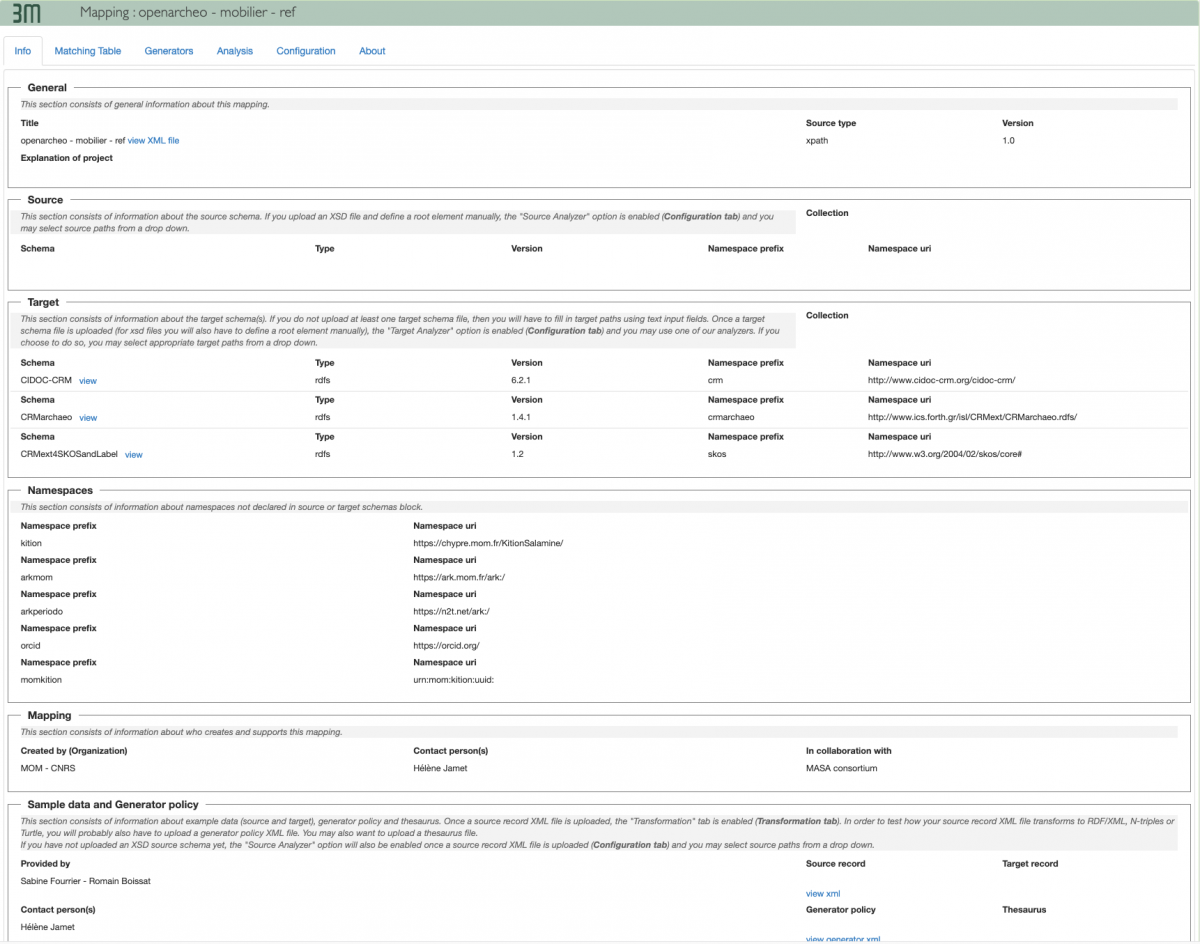
Cette première sélection sera, suivie d’une seconde sélection car nous souhaitons appliquer le schéma OpenArchaeo qui est lui-même une sélection, au sein du CIDOC-CRM et de l’extension CRMarchaeo, des classes et propriétés les plus utiles pour la modélisation des données d’une fouille archéologique.
La seconde étape consiste à établir des relations entre la description de chaque ressource de notre fichier XML avec les différentes classes du CIDOC-CRM en respectant les règles hiérarchiques et les enchainements de propriétés autorisés par l’ontologie. Pour cela nous utiliserons les Generator et les Matching Table de 3M. Le Generator permet la spécification d’une relation, tandis que la Matching Table est l’enchainement de classes et propriétés qui forment la modélisation. Dans les Matching Table, une fois que l’on a sélectionné une classe du CIDOC-CRM, 3M nous indique les enfants autorisés hiérarchiquement avec la classe que l’on vient de sélectionner. Ainsi les relations et enchainements ne peuvent être contraires aux règles de l’ontologie. Chaque ressource du fichier RDF de sortie est alors identifiée de manière unique en regard de l’ontologie par une URI (identifiant unique d’une ressource). Pour éviter des répétitions dans l’appariement, on crée des variables auxquelles on peut faire appel. Cela permet d’éviter de répéter par exemple l’auteur d’un document à chaque ressource. Il suffit de l’identifier comme une variable fixe une seule fois et chaque ressource ayant besoin de cette qualification y fera référence. Nous sommes bien ici dans l’idée de relier toutes les données entre elles.
3 : Generator (cliquer pour agrandir l'image)
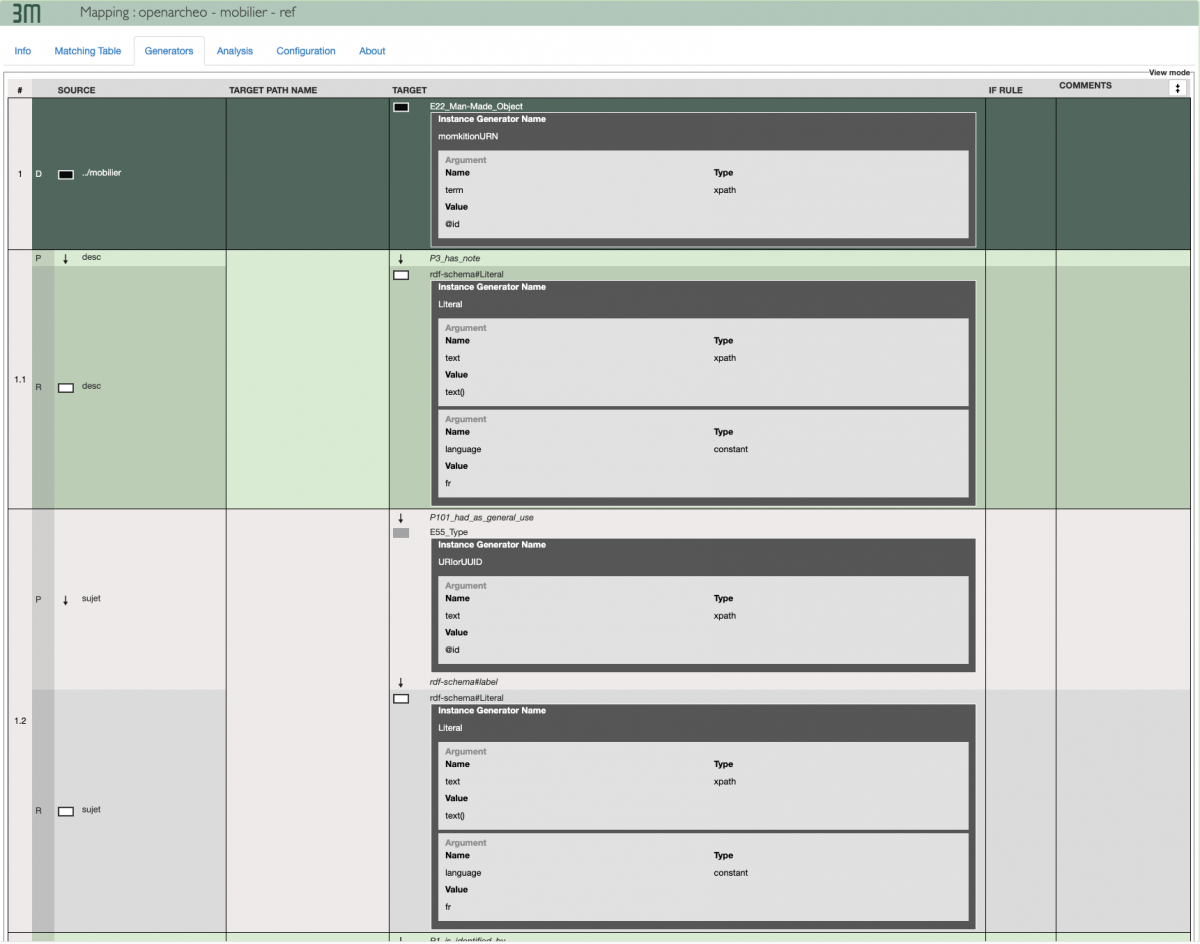
4 : Matching Table (cliquer pour agrandir l'image)

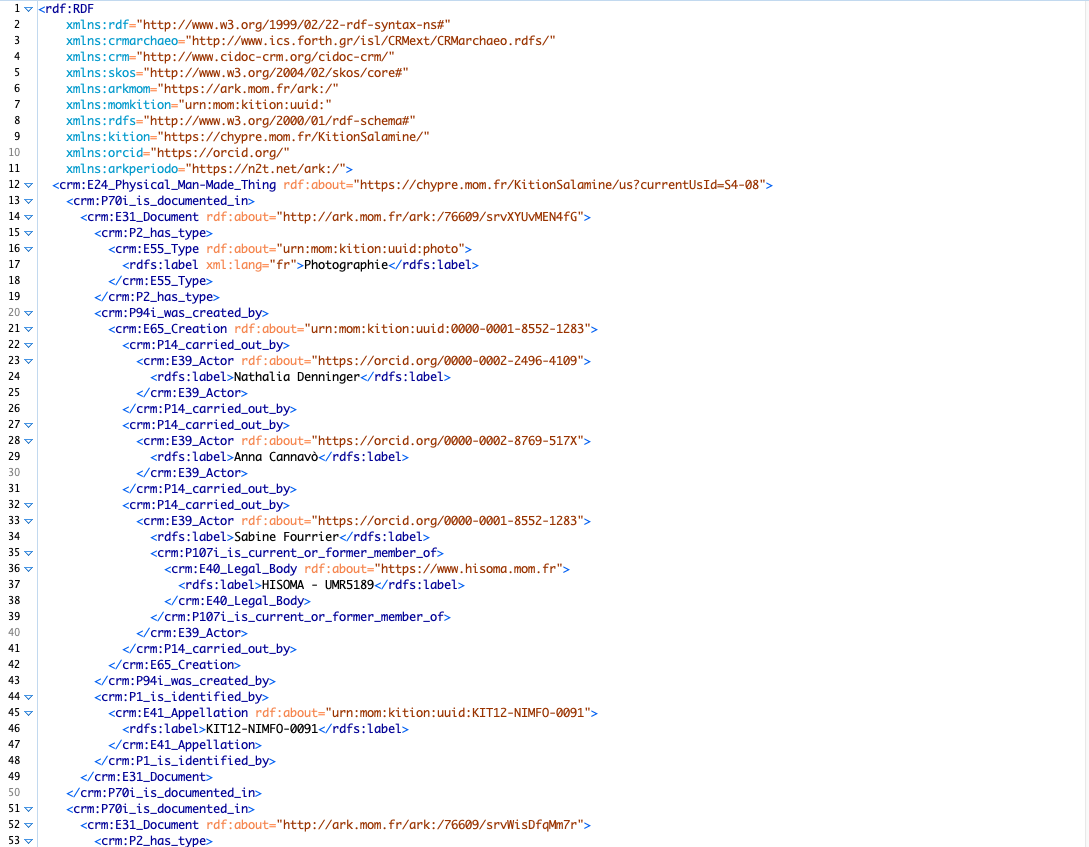
Enfin la dernière étape, une fois l’appariement entre l’ontologie et nos données terminé, est de lancer la transformation pour pouvoir vérifier que tous les appariements sont corrects. Des allers-retours permettront dès cet instant de corriger les erreurs dans les Matching Table jusqu’à arriver à un résultat satisfaisant et conforme. Le but est d’aboutir à un fichier RDF où chaque ressource est identifiée par une URI avec un identifiant unique et pérenne type Ark ou Handle pour les ressources internes au jeu de données. Si les ressources sont externes, elles pointent alors vers un référentiel (Geonames : lieux, Perio.do : temps, PACTOLS : sujets, ORCID : personne, etc.). Une fois que l’appariement est validé sur notre échantillon, il suffit d’exporter notre Generator depuis l’interface graphique et de l’importer dans le moteur X3ML en ligne de commande pour l’appliquer à l’ensemble de notre jeu de données. Nous obtenons ainsi un ensemble de triplets RDF corrects que l’on peut déposer dans un Triple Store pour que des requêtes d’interrogations SPARQL soient réalisées.
5 : Page Transformation (cliquer pour agrandir l'image)
![]()
6 : Fichier RDF de sortie (cliquer pour agrandir l'image)
Pour conclure, ce billet ne se veut qu’une porte d’entrée vers l’utilisation de l’ontologie du CIDOC-CRM et sa manipulation à l’aide d’un outil comme 3M. De nombreuses ressources en ligne existent pour prendre en main l’ontologie (documentation officielle), trouver des exemples de modélisation (OpenArchaeo et OntoMe) ou des retours d’expériences de projets dont les données sont alignées sur le CIDOC-CRM. De nombreuses équipes travaillent maintenant à rendre leurs données interopérables pour intégrer leur travail et leurs jeux de données au sein dans l’Open Data en appliquant les principes FAIR et notamment l’Interoperablegrâce au CIDOC-CRM, sans oublier les trois autres principes (Findable, Accessible, Reusable) tout aussi nécessaires.

, abbaye de prémontrés : étude des transformations de l’église et des bâtiments abbatiaux en exploitation agricole (XIXe-XXe) © N. Reveyron, laboratoire ArAr.")
 © Valérie Merle, laboratoire ArAr")
, IIIe s. apr. J.-C. © S. Fourrier, laboratoire HiSoMA : site de Kition-Bamboula (mission archéologique française de Kition)")

 : site de Kition-Bamboula (mission archéologique française de Kition)")




. © laboratoire HiSoMA")


 © G. Charpentier")



